

In recent years, knowledge graphs have become an important tool for organizing and accessing large volumes of enterprise data in diverse industries — from healthcare to industrial, to banking and insurance, to retail and more.
A knowledge graph is a graph-based database that represents knowledge in a structured and semantically rich format. This could be generated by extracting entities and relationships from structured or unstructured data, such as text from documents. A key requirement for maintaining data quality in a knowledge graph is to base it on standard ontology. Having a standardized ontology often involves the cost of incorporating this ontology in the software development cycle.
Organizations can take a systematic approach to generating a knowledge graph by first ingesting a standard ontology (like insurance risk) and using a large language model (LLM) like GPT-3 to create a script to generate and populate a graph database.
The second step is to use an LLM as an intermediate layer to take natural language text inputs and create queries on the graph to return knowledge. The creation and search queries can be customized to the platform in which the graph is stored — such as Neo4j, AWS Neptune or Azure Cosmos DB.
Event
Transform 2023
Join us in San Francisco on July 11-12, where top executives will share how they have integrated and optimized AI investments for success and avoided common pitfalls.
Combining ontology and natural language techniques
The approach outlined here combines ontology-driven and natural language-driven techniques to build a knowledge graph that can be easily queried and updated without extensive engineering efforts to build bespoke software. Below we provide an example of an insurance company, but the approach is universal.
The insurance industry is faced with many challenges, including the need to manage large amounts of data in a way that is both efficient and effective. Knowledge graphs provide a way to organize and access this data in a structured and semantically rich format. This can include nodes, edges and properties where nodes represent entities, edges represent relationships between entities and properties represent at-tributes of entities and relationships.
There are several benefits to using a knowledge graph in the insurance industry. First, it provides a way to organize and access data that is easy to query and update. Second, it provides a way to represent knowledge in a structured and semantically rich format, which makes it easier to analyze and interpret. Finally, it provides a way to integrate data from different sources, including structured and unstructured data.
Below is a 4 step approach. Let’s review each step in detail.
Approach
Step 1: Studying the ontology and identifying entities and relations
The first step in generating a knowledge graph is to study the relevant ontology and identify the entities and relationships that are relevant to the domain. An ontology is a formal representation of the knowledge in a domain, including the concepts, relations and constraints that define the domain. Insurance risk ontology defines the concepts and relationships that are relevant to the insurance domain, such as policy, risk and premium.
The ontology can be studied using various techniques including manual inspection and automated methods. Manual inspection involves reading the ontology documentation and identifying the relevant entities and relationships. Automated methods use natural language processing (NLP) techniques to extract the entities and relationships from the ontology documentation.
Once the relevant entities and relationships have been identified, they can be organized into a schema for the knowledge graph. The schema defines the structure of the graph, including the types of nodes and edges that will be used to represent the entities and relationships.
Step 2: Building a text prompt for LLM to generate schema and database for ontology
The second step in generating a knowledge graph involves building a text prompt for LLM to generate a schema and database for the ontology. The text prompt is a natural language description of the ontology and the desired schema and database structure. It serves as input to the LLM, which generates the Cypher query for creating and populating the graph database.
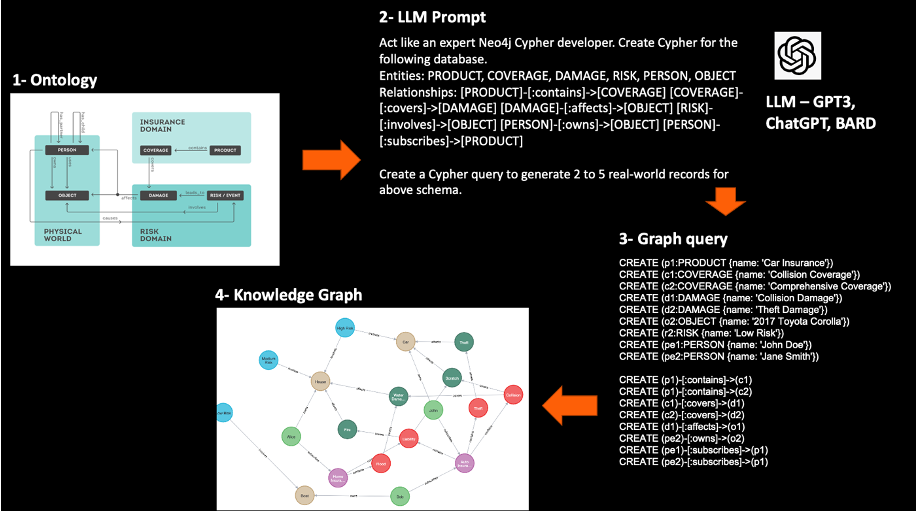
The text prompt should include a description of the ontology, the entities and relationships that were identified in step 1, and the desired schema and database structure. The description should be in natural language and should be easy for the LLM to understand. The text prompt should also include any constraints or requirements for the schema and database, such as data types, unique keys and foreign keys.
For example, a text prompt for the insurance risk ontology might look like this:
“Create a graph database for the insurance risk ontology. Each policy should have a unique ID and should be associated with one or more risks. Each risk should have a unique ID and should be associated with one or more premiums. Each premium should have a unique ID and should be associated with one or more policies and risks. The database should also include constraints to ensure data integrity, such as unique keys and foreign keys.”
Once the text prompt is ready, it can be used as input to the LLM to generate the Cypher query for creating and populating the graph database.
Step 3: Creating the query to generate data
The third step in generating a knowledge graph involves creating the Cypher query to generate data for the graph database. The query is generated using the text prompt that was created in step 2 and is used to create and populate the graph database with relevant data.
The Cypher query is a declarative language that is used to create and query graph databases. It includes commands to create nodes, edges, and relationships between them, as well as commands to query the data in the graph.
The text prompt created in step 2 serves as input to the LLM, which generates the Cypher query based on the desired schema and database structure. The LLM uses NLP techniques to understand the text prompt and generate the query.
The query should include commands to create nodes for each entity in the ontology and edges to represent the relationships between them. For example, in the insurance risk ontology, the query might include commands to create nodes for policies, risks and premiums, and edges to represent the relationships between them.
The query should also include constraints to ensure data integrity, such as unique keys and foreign keys. This will help to ensure that the data in the graph is consistent and accurate.
Once the query is generated, it can be executed to create and populate the graph database with relevant data.
Ingesting the query and creating a knowledge graph
The final step in generating a knowledge graph involves ingesting the Cypher query and creating a graph database. The query is generated using the text prompt created in step 2 and executed to create and populate the graph database with relevant data.
The database can then be used to query the data and extract knowledge. The graph database is created using a graph database management system (DBMS) like Neo4j. The Cypher query generated in step 3 is ingested into the DBMS, which creates the nodes and edges in the graph database.
Once the database is created, it can be queried using Cypher commands to extract knowledge. The LLM can also be used as an intermediate layer to take natural language text inputs and create Cypher queries on the graph to return knowledge. For example, a user might input a question like “Which policies have a high-risk rating?” and the LLM can generate a Cypher query to extract the relevant data from the graph.
The knowledge graph can also be updated as new data becomes available. The Cypher query can be modified to include new nodes and edges, and the updated query can be ingested into the graph database to add the new data.
Advantages of this approach
Standardization
Ingesting a standard ontology like insurance risk ontology provides a framework for standardizing the representation of knowledge in the graph. This makes it easier to integrate data from different sources and ensures that the graph is semantically consistent. By using a standard ontology, the organization can ensure that the data in the knowledge graph is consistent and standardized. This makes it easier to integrate data from multiple sources and ensures that the data is comparable and meaningful.
Efficiency
Using GPT-3 to generate Cypher queries for creating and populating the graph database is an efficient way to automate the process. This reduces the time and resources required to build the graph and ensures that the queries are syntactically and semantically correct.
Intuitive querying
Using LLM as an intermediate layer to take natural language text inputs and create Cypher queries on the graph to return knowledge makes querying the graph more intuitive and user-friendly. This reduces the need for users to have a deep understanding of the graph structure and query language.
Productivity
Traditionally, developing a knowledge graph involved custom software development, which can be time-consuming and expensive. With this approach, organizations can leverage existing ontologies and NLP tools to generate the query, reducing the need for custom software development.
Another advantage of this approach is the ability to update the knowledge graph as new data becomes available. The Cypher query can be modified to include new nodes and edges, and the updated query can be ingested into the graph database to add the new data. This makes it easier to maintain the knowledge graph and ensure that it remains up-to-date and relevant.
Dattaraj Rao is chief data scientist at Persistent.
DataDecisionMakers
Welcome to the VentureBeat community!
DataDecisionMakers is where experts, including the technical people doing data work, can share data-related insights and innovation.
If you want to read about cutting-edge ideas and up-to-date information, best practices, and the future of data and data tech, join us at DataDecisionMakers.
You might even consider contributing an article of your own!
Read More From DataDecisionMakers







